Table of Contents
A Multithreaded Buddhabrot Renderer
After completing the Single Threaded Buddhabrot Renderer, you should have a program that can render images using the Buddhabrot rendering technique. However, you probably noticed that this computation is incredibly slow.
Modern computers often have many processors to use for computations. However, unless you take steps to leverage these processors, your program will only run on one processor, not taking full advantage of your computer’s capabilities.
This assignment we will update the Buddhabrot program to be multithreaded, so that it can take advantage of multiple processors. At the end of this assignment, you should have a program that can run much faster on a multi-core system.
Approach
There are many ways to take a sequential computation and parallelize it. The best approach to use often depends on the nature of the problem being solved. We need to split the sequential computation into multiple parallel computations that can be executed on separate threads. If two threads must interact with shared data, we need to synchronize their access to the data to ensure that our program doesn’t generate spurious results. Of course, synchronization will generally slow down your program, so it’s important to break down the problem such that threads interact with each other as little as possible to complete their task.
The Buddhabrot computation seems straightforward to parallelize:
- The process of generating a random complex point in the range \((-2 - 1.5i)\) to \((1 + 1.5i)\), seeing if the point escapes from the Mandelbrot set, and recording its escape trajectory, can progress independent of any other computations. Thus, we can have multiple threads doing this calculation in parallel.
- The process of updating the image based on coordinates’ escape trajectories is a different matter, because it’s quite possible that two threads will need to update the same pixel. Even a seemingly one-step operation like incrementing a count, may be executed by the processor as a multi-step operation (read value, increment, write back value). If we don’t control how threads access the image, we could easily end up with wrong results.
We could have multiple threads coordinate access to the image by guarding the image with a mutex, but having multiple threads contend over a single image-lock could become a bottleneck. Additionally, updating a single image from multiple threads can generate performance issues with the hardware caches. (If you are curious about this, you should look at cache coherence protocols that multi-core processors must implement. These protocols keep multiple independent caches of a single shared memory synchronized, so that programs don’t see invalid or outdated results.)
To avoid this potential bottleneck - and to give us a more interesting and typical concurrency problem to solve - we will follow a producer-consumer pattern in our implementation. We will have \(N\) producer threads that are looking for points that escape from the Mandelbrot set, recording their escape trajectories. These \(N\) producers will store their results into a thread-safe queue. A “thread-safe queue” is simply a queue that can be used by multiple threads without generating spurious results, crashing, misplacing values, or having other such concurrency bugs. It is a very common way to allow different components of a concurrent/parallel system to interact with each other.
Finally, one consumer thread will be responsible for reading the results from the queue, and updating the image appropriately. Since only one thread will be accessing the image, we don’t need to synchronize these accesses. In our program, the consumer will simply be the main thread (i.e. the one that is started by the OS when we run our program); it will initialize the producer threads, consume their input until they are done, and then output the resulting image data.
Pictorially, it will look like this:
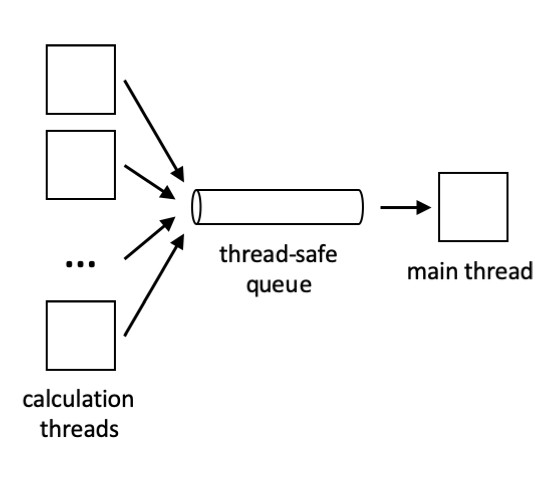
Thread-Safe Queues
The simplest implementation of a thread-safe queue uses a single mutex to guard the queue’s contents. Both producers and consumers must acquire the mutex before interacting with the queue’s internal state. With C++11 and later, the C++ Standard Library includes a number of thread synchronization primitives, including std::mutex and std::condition_variable, which make implementing simple thread-safe data structures straightforward.
The queue’s contents can be managed with an existing C++ collection class like the std::deque (“deque” is short for “double-ended queue”), which is particularly well suited to this usage pattern: elements can be added to the back of the std::deque in constant time, and removed from the front in constant time. In this way, the std::deque is better for building queues than the std::vector, since vector takes a linear amount of time to remove elements from the front - it must copy all elements over by one location, every time the first element is removed.
There are other ways to construct thread-safe queues. The above approach is one of the simplest, and also the slowest, since threads will frequently contend for the single mutex guarding the queue. More advanced thread-safe queues use a lock per element to achieve much lower lock contention. Finally, there are also lock-free and wait-free queues which can be extremely fast - but these approaches are also extremely difficult to implement correctly, and can be subject to extremely subtle bugs caused by unexpected hardware and compiler behaviors. Because of this, many projects stick to lock-based approaches because it is simply easier to ensure their correctness.
Differences in Speed
A very important issue with producer-consumer systems is how they behave when producers and consumers run at different speeds. This becomes particularly pronounced if there are many more producers than consumers, or many more consumers than producers.
What happens if the consumer is faster than the producer? In this case, the consumer will drain the queue frequently, resulting in the consumer having no work to do. This is fine, as long as the consumer can passively wait.
Passive waiting is very easy to implement using mutexes and condition variables.
- The consumer already must acquire a mutex that guards the queue, and if the queue is empty then the consumer can simply wait on an associated condition variable. This wait operation will automatically release the mutex, allowing other threads to access the queue.
- When a producer finally puts something into the queue, it must first acquire the queue’s mutex. Then the producer can notify any consumers waiting on the condition variable, so they know it’s time to wake up.
Condition variables allow threads to coordinate access to shared resources, allowing threads to passively wait, and to wake up other threads when some condition becomes true.
OK, easy enough. But, what happens if the producer is faster than the consumer?
If a producer is producing data faster than a consumer can consume it, then the queue will simply grow, buffering the extra data. The problem is, if the producer is always faster than the consumer, then the queue will grow larger and larger, until all available memory is consumed by the queue. Then your program crashes!
Because of this, we need a way for slow consumers to force faster producers to slow down. This is called back-pressure, and again this is a critical feature for producer-consumer systems to provide.
Our queue can force fast producers to slow down by maintaining an upper bound on how many elements may be stored in the queue. If a producer tries to put data into a full queue, then it must passively wait until the queue has some space. Again, this can be implemented very easily using a condition variable.
Buddhabrot Updates
As stated earlier, you will update your Buddhabrot program you created in Assignment 2 to support multiple threads of execution. To do so, you will create a bounded thread-safe queue, and make a few other changes to your program. Read on for details…
Passing mandelbrot_point_info Objects
We kept things simple and had our compute_mandelbrot() function return mandelbrot_point_info objects. This was fine for how we were using the function, but once we start passing these objects into C++ STL collections, we need to think more carefully about how much we may be copying data.
There are two ways of handling this. Both work equally well and both rely on avoiding to create copies of data structures in memory without any need:
- Heap allocate the
mandelbrot_point_infoinstance on the heap and manage the returned pointer using astd::shared_ptr. In this case, instead of copying the wholemandelbrot_point_infoinstance, the code will copy the (shared) pointer to it, thus reducing the related overheads. The use ofstd::shared_ptrinstead of raw pointers makes sure that the memory will be released once no code references a particular instance anymore. - Employ C++ move semantics when inserting and extracting the
mandelbrot_point_infoinstances into and out of the queue. C++ move semantics rely on special handling of function arguments (and function return values) in a way that avoids copying the array of coordinates that are stored in themandelbrot_point_infoinstances.
While the second approach is more idiomatic in modern C++, it may be more difficult to ‘get it right’. For this reason, we suggest you implement your queue to store the shared pointers to the mandelbrot_point_info instances instead.
Update your
compute_mandelbrot()function to allocate themandelbrot_point_infostruct off of the heap. Don’t just usenewto allocate this object; you need to follow modern C++ best practices and wrap the allocation with astd::shared_ptrthat will free the allocation when no one is using it any longer.Update your
compute_mandelbrot()function to return astd::shared_ptr<mandelbrot_point_info>. Again, don’t usenewto allocate the object. C++11 and later provide the function templatesstd::make_shared<T>()andstd::make_unique<T>()which handle both heap allocation and smart-pointer initialization in one step.
In most modern C++ programs you write, you should very rarely use new and delete. Rather, you should strive to use std::make_shared<T>() and std::make_unique<T>(), so you don’t have to worry about deleting objects. You tend to only need new and delete when you are creating your own data structures. Always try to find a way to use smart pointers to manage memory.
Concurrent Bounded Queue Implementation
In a file concurrent_bounded_queue.hpp (and optionally concurrent_bounded_queue.cpp, if you prefer separating class declarations and definitions), implement a concurrent_bounded_queue class that has the characteristics described earlier:
- The queue should use a
std::dequeinternally, because we don’t want to replicate work that has already been done for us. - Use one
std::mutexmember to guard all gets and puts on the queue. - Use one
std::condition_variablemember to allow consumers to passively wait when the queue is empty, and anotherstd::condition_variablemember to allow producers to passively wait when the queue is full.
The queue should have these public member functions:
concurrent_bounded_queue(int max_items)for specifying the max size of the queue at initialization.void put(std::shared_ptr<mandelbrot_point_info> item)for storing an item to the queue, subject to the behaviors described above.std::shared_ptr<mandelbrot_point_info> get()for reading an item from the queue, subject to the behaviors described above.
The queue should not need a destructor, because we are using smart pointers to manage all heap-allocated memory. If your queue has a destructor, you are doing it wrong…
You might also notice that it doesn’t make sense for this queue to support copy-initialization or copy-assignment, so delete these operations in your class declaration.
Don’t forget to properly document your class, including all data members and member functions.
Main Program Updates
Once you have a concurrent bounded queue implemented, you can start to restructure your program to spin up \(N\) producer threads to generate data, and then have the main thread use their results to update the image. This is mostly straightforward, but there are a few nuances to be aware of.
Producer Thread-Function
For the Buddhabrot renderer to start multiple threads, your program must provide a function for the std::thread instances to run. In your buddhabrot.cpp file, implement a function like this:
void generate_buddhabrot_trajectories(
int num_points, int max_iters, concurrent_bounded_queue &queue);
This should be a straightforward refactoring of your previous work. However, this function should only store points that are not in the Mandelbrot set into the concurrent queue. Why store points that will just be discarded by the main thread?
Finally, the function needs a way to say when it is finished producing; otherwise, the consumer won’t know when to stop asking for more data. An easy way to do this is to put some kind of “finished” value into the queue. The simplest “finished” value would be a smart-pointer holding the nullptr value. (This is what the shared_ptr default constructor creates.) When the consumer sees this value, it will know that another producer has finished.
In your main thread you can check for validity of any shared_ptr object by simply saying:
std::shared_ptr<mandelbrot_point_info> p = ...;
if (p) {
// the shared_ptr p is valid
}
The main() Function
In our program, the main() function will run through this sequence of steps. These are very similar to what you have implemented in Assignment 2.
- Parse command-line arguments.
- Initialize the concurrent bounded queue with some upper bound (e.g. 100 items).
- Initialize the image that will store the final results.
- Start up \(N\) producer threads (as specified by the user, use one thread as the default).
- Consume results from the concurrent bounded queue, until all \(N\) producers are finished. The results are used to update the image contents.
- When all \(N\) producers are finished, the
main()function must callthread::join()on all producer threads. Failure to do this will cause the C++ runtime to terminate your program abnormally. - Of course, don’t forget to output the image to standard output!
The subsequent sections describe the details for these steps.
Command-Line Arguments
Previously, you would invoke the Buddhabrot program like this:
./build/work/buddhabrot/buddhabrot -s 600 -p 50000000 -i 5000 -o image.bmp
Add another command line option
-t, that allows to specify the number of producer threads to start:# Start 4 producer threads! ./build/work/buddhabrot/buddhabrot -s 600 -p 50000000 -i 5000 -t 4 -o image.bmpIf this command line option is not provided by the user, your program should create one thread for computing the Mandelbrot trajectories.
Don’t forget to modify the help string and the printed summary information accordingly.
Update the code that checks the number of arguments, and that complains to the user if the arguments aren’t correct. Make sure to parse the number of threads that the user specifies on the command-line.
Initializing the Queue and Image
Initializing the concurrent bounded queue and the image should be straightforward, so we won’t say anything else about it here.
Initializing the \(N\) Producer Threads
The main function will need to create the number of threads requested by the user (by default, one thread). You can use your generate_buddhabrot_trajectories() function as the thread function. Note that the queue must be passed by reference (you want all threads operating on the same queue object), so you may need to employ the std::ref() function. (The std::ref() function is very simple; it just wraps a reference with an object so that the reference can be passed by-value. Slightly weird, but not very exciting.)
Sometimes the number of points may not be evenly divisible by the number of producers (threads). Make sure that your program generates exactly the number of points that the user requests.
Consuming Results from the Queue
Consuming results from the queue and using them to update the image contents should be very similar to the previous week’s version of the program. There is really only one nuance - you will need to keep track of when producers are finished generating data. If you use a smart pointer to nullptr then this will be very easy; you can just keep a count of how many times you have seen a nullptr come through (an ‘invalid’ shared_ptr), and when all producers have finished, you know the program is done.
Call thread::join() on All Producers
Once each producer thread is done, the main thread must call join() on the thread. Failure to do so will cause the C++ runtime to complain loudly. The easiest way to do this is to wait until all producer threads have finished running, and then call join() on all of them. Alternatively you can use std::jthread that implicitly joins with the thread in its destructor.
This means you will need to keep track of the threads that you started in an earlier step. Hint: A std::vector<std::thread> might be a good option for doing this (alternatively std::vector<std::jthread>).
Outputting the Image
This should be identical to last time, so we won’t say anything about this.
Testing
Once you have completed the above steps, you can start exercising your program to see if it’s any faster. You may want to start out with only one producer thread at first, to make sure your program works properly:
./build/work/buddhabrot/buddhabrot -s 200 -p 1000000 -i 1000 -t 1 -o img_1000.bmp
If the output looks correct, and your program terminates when it’s supposed to, then try it with two or more threads:
./build/work/buddhabrot/buddhabrot -s 200 -p 1000000 -i 1000 -t 2 -o img_1000.bmp
Your program should continue to generate correct-looking images, but it should be faster (if you run on a computer with multiple CPUs).
Multithreaded Performance
As long as multiple CPUs are available, using multiple threads should make our program faster. There are limits, of course: if you have 4 CPUs and you run with 6 producer threads (and one consumer thread), at least 3 CPUs will have to run more than one thread, and this will likely be slower than just running with 3 or 4 producers. In this program, the CPU is the bottleneck, so you want to use the same number of threads as you have processors; using more threads than this will simply waste time.
To explore this, you can measure the performance of your program with the UNIX time command:
# Redirect the program output to /dev/null so we can ignore it
time ./build/work/buddhabrot/buddhabrot -s 1000 -p 10000000 -i 1000 -t 1 -o /dev/null
real 1m47.544s <-- This is the wall-clock time
user 1m55.108s
sys 0m14.927s
If you increase the number of threads to two, and there are two CPUs to use, you should see the program run approximately twice as fast:
time ./build/work/buddhabrot/buddhabrot -s 1000 -p 10000000 -i 1000 -t 2 -o /dev/null
real 0m56.543s <-- 1.9x faster than 1 thread
user 1m59.812s
sys 0m16.470s
And with three threads:
time ./build/work/buddhabrot/buddhabrot -s 1000 -p 10000000 -i 1000 -t 3 -o /dev/null
real 0m40.740s <-- 2.6x faster than 1 thread
user 2m2.805s
sys 0m15.734s
These tests were run on a computer with 32 CPUs. Why is using three producer threads not three times faster than using one producer thread? The answer lies in how we have structured the computation: the single consumer must still process all of the data from the producers, and this is a sequential task. Additionally, our simple queue with a single mutex reduces the amount of time the producers can operate in parallel.
Add a table to
results/answers.mdwith timings for your Buddhabrot implementation when using different numbers of threads.
Most parallel programs will still include some work that must be performed sequentially. Because of this, there is a limit to the speedup that may be achieved through parallelizing the task. This is known as Amdahl’s Law, and is a very important principle. In general, when parallelizing computations, you want to have as little sequential work as possible, so that each additional CPU/thread will produce a big benefit.
There are many things we could do to make our Buddhabrot renderer use threads and CPUs more efficiently - try it out if you are interested!
All Done
Once you have finished testing and debugging your program, submit these files as part of your assignment:
concurrent_bounded_queue.hppandconcurrent_bounded_queue.cpp(if necessary)mandelbrot.hppandmandelbrot.cppbuddhabrot.hppandbuddhabrot.cpp
Next up: Submission