Table of Contents
Warmup
Preliminaries
std::futures
C++ provides the mechanism to enable execution of a function call as an asynchronous task. Its semantics are important. Consider the example we have been using in lecture.
size_t bank_balance = 300;
static std::mutex atm_mutex;
static std::mutex msg_mutex;
size_t withdraw(const std::string& msg, size_t amount) {
std::lock(atm_mutex, msg_mutex);
std::lock_guard<std::mutex> message_lock(msg_mutex, std::adopt_lock);
std::cout << msg << " withdraws " << std::to_string(amount) << std::endl;
std::lock_guard<std::mutex> account_lock(atm_mutex, std::adopt_lock);
bank_balance -= amount;
return bank_balance;
}
int main() {
std::cout << "Starting balance is " << bank_balance << std::endl;
std::future<size_t> bonnie = std::async(std::launch::async, withdraw, "Bonnie", 100);
std::future<size_t> clyde = std::async(std::launch::async, deposit, "Clyde", 100);
std::cout << "Balance after Clyde's deposit is " << clyde.get() << std::endl;
std::cout << "Balance after Bonnie's withdrawal is " << bonnie.get() << std::endl;
std::cout << "Final bank balance is " << bank_balance << std::endl;
return 0;
}
Here we just show the withdraw function. Refer to the full source code for complete implementation work/warmup/bonnie_and_clyde.cpp.
Note that we have modified the code from lecture so that the deposit and withdrawal functions return a value, rather than just modifying the global state.
Compile and run the bonnie_and_clyde program several times. Does it always return the same answer?
On my laptop I ran the example and obtained the following results (which were different every time):
$ ./build/work/warmup/bonnie_and_clyde
Starting balance is 300
Bonnie withdraws 100
Balance after Clyde's deposit is Clyde deposits 100
300
Balance after Bonnie's withdrawal is 200
Final bank balance is 300
$ ./build/work/warmup/bonnie_and_clyde
Starting balance is 300
Balance after Clyde's deposit is Clyde deposits 100
Bonnie withdraws 100
400
Balance after Bonnie's withdrawal is 300
Final bank balance is 300
$ ./build/work/warmup/bonnie_and_clyde
Starting balance is 300
Bonnie withdraws 100
Clyde deposits 100
Balance after Clyde's deposit is 300
Balance after Bonnie's withdrawal is 200
Final bank balance is 300
$ ./build/work/warmup/bonnie_and_clyde
Starting balance is 300
Balance after Clyde's deposit is Bonnie withdraws 100
Clyde deposits 100
300
Balance after Bonnie's withdrawal is 200
Final bank balance is 300
See if you can trace out how the different tasks are running and being interleaved. Notice that everything is protected from races – we get the correct answer at the end every time.
Note the ordering of calls in the program:
std::future<size_t> bonnie = std::async(std::launch::async, withdraw, "Bonnie", 100);
std::future<size_t> clyde = std::async(std::launch::async, deposit, "Clyde", 100);
std::cout << "Balance after Clyde's deposit is " << clyde.get() << std::endl;
std::cout << "Balance after Bonnie's withdrawal is " << bonnie.get() << std::endl;
That is, the ordering of the calls is Bonnie makes a withdrawal, Clyde makes a deposit, we get the value back from Clyde’s deposit and then get the value back from Bonnie’s withdrawal. In run 0 above, that is how things are printed out: Bonnie makes a withdrawal, Clyde makes a deposit, we get the value after Clyde’s deposit, which is 300, and we get the value after Bonnie’s withdrawal, which is 200. Even though we are querying the future values with Clyde first and Bonnie second, the values that are returned depend on the order of the original task execution, not the order of the queries.
But let’s look at run 2. In this program, there are three threads: the main thread (which launches the tasks), the thread for the bonnie task and the thread for the clyde task. The first thing that is printed out after the tasks are launched is from Clyde’s deposit. But, before that statement can finish printing in its entirety, the main thread interrupts and starts printing the balance after Clyde’s deposit. The depositing function isn’t finished yet, but the get() has already been called on its future. That thread cannot continue until the clyde task completes and returns its value. The clyde task finishes its cout statement with “100”. But then the bonnie task starts running - and it runs to completion, printing “Bonnie withdraws 100” and it is done. But, the main thread was still waiting for its value to come back from the clyde task – and it does – so the main thread completes the line “Balance after Clyde’s deposit is” and prints “400”. Then the next line prints (“Balance after Bonnie’s withdrawal”) and the program completes.
Try to work out the sequence of interleavings for run 1 and run 3. There is no race condition here – there isn’t ever the case that the two tasks are running in their critical sections at the same time. However, they can be interrupted and another thread can run its own code – it is only the critical section code itself that can only have one thread executing it at a time. Also note that the values returned by bonnie and clyde can vary, depending on which order they are executed, and those values are returned by the future, regardless of which order the futures are evaluated.
std::future::get
Modify your
bonnie_and_clydeprogram in the following way. Add a line in the function after the printout from Bonnie’s withdrawal to double check the value:std::cout << "Balance after Clyde's deposit is " << clyde.get() << std::endl; std::cout << "Balance after Bonnie's withdrawal is " << bonnie.get() << std::endl; std::cout << "Double checking Clyde's deposit " << clyde.get() << std::endl;(The third line above is the one you add.)
Answer the following questions in
results/answers.md:
- What happens when you compile and run this example?
- Why do you think the designers of C++ and its standard library made futures behave this way?
Callables
We have looked at two ways of specifying concurrent work to be executed in parallel: threads and tasks. Both approaches take an argument that represents the work that we want to be done (along with additional arguments to be used by that first argument). One kind of thing that we can pass is a function.
void pi_helper(int begin, int end, double h) {
for (int i = begin; i < end; ++i) {
pi += (h*4.0) / (1.0 + (i*h*i*h));
}
}
int main() {
// ...
std::thread(pi_helper, 0, N/4, h); // pass function
return 0;
}
The interfaces to thread and to async are quite general. In fact, the type of the thing being passed in is parameterized. What is important about it is not what type it is, but rather what kinds of expressions can be applied to it.
To be more concrete, the C++11 declaration for async is the following:
template <typename Function, typename... Args>
std::future<std::invoke_result_t<Function&&, Args&&...>>
async(Function&& f, Args&&... args );
There are a number of advanced C++ features being used in this declaration, but the key thing to note is that, indeed, the first argument f is of a parameterized type (Function).
The requirements on whatever type is bound to Function are not that it be a function, but rather that it be Callable. Meaning, if f is Callable, we can say this as a valid expression:
f();
Or, more generally
f(args...);
This is purely syntactic – the requirement is that we be able to write down the name of the thing that is Callable, and put some parentheses after it (in general with some other things inside the parentheses).
Of course, a function is one of the things that we can write down and put some parentheses after. But we have also seen in C++ that we can overload operator() within a class. Objects of a class with operator() can be written down with parentheses – just like a function call. In fact, this is what we have been doing to index into Vector and Matrix.
We can also create expressions that themselves are functions (“anonymous functions” or lambda expressions).
One way of thinking about thread and async is that they are “higher-order functions” – functions that operate on other functions. As you become more advanced in your use of C++, you will find that many common computational tasks can be expresses as higher order functions.
A bit more information about function objects and lambdas can be found as excursus: Function Objects and Lambda Functions. Lambdas are also covered in the lectures. There is also an example of function objects for our bank account example in the file work/warmup/bonnie_and_clyde_function_object.cpp.
Parallel Roofline
We have been using the roofline model to provide some insight (and some quantification) of the performance we can expect for sequential computation, taking into account the capabilities of the CPU’s compute unit as well as the limitations imposed by the memory hierarchy. These same capabilities and limitations apply once we move to multicore (to parallel computing in general). Some of the capabilities scale with parallelism – the available compute power scales with number of cores, as does the bandwidth for any caches that are directly connected to cores. The total problem size that will fit into cache also scales. Shared cache and main memory do not.
For the intrepid, you can create roofline diagrams for a varying amount of parallelism by running the ERT on 2, 4, and 8 threads / cores:
$ cd ert
$ ./run.openmp.2.sh
$ ./run.openmp.4.sh
$ ./run.openmp.8.sh
On some platforms, you may have to explicitly mark the scripts
ert/run*.shas being executable to be able to run the benchmark. Please execute the following commands if you receive a ‘Permission denied’ error. This has to be done once only, not every time you open the VSCode project.$ cd ert $ chmod +x *.sh ert Scripts/*.py
You can get the sequential profile by running run.sh as described in assignment 2.
Running these scripts may take a while (up to 20-30 minutes), please be patient and try not to do anything else on your computer during this time.
Theoretically, the maximum performance of 8 cores should be 8 times than the maximum performance of single core, as well as the maximum bandwidth of L1/L2 caches (as they are private). The main memory bandwidth of 8 cores should stay the same as the main memory bandwidth of single core.
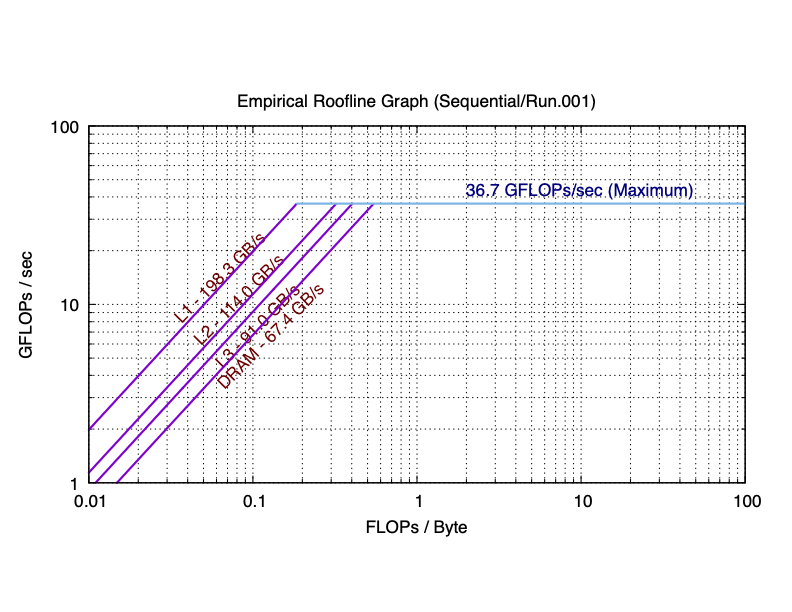
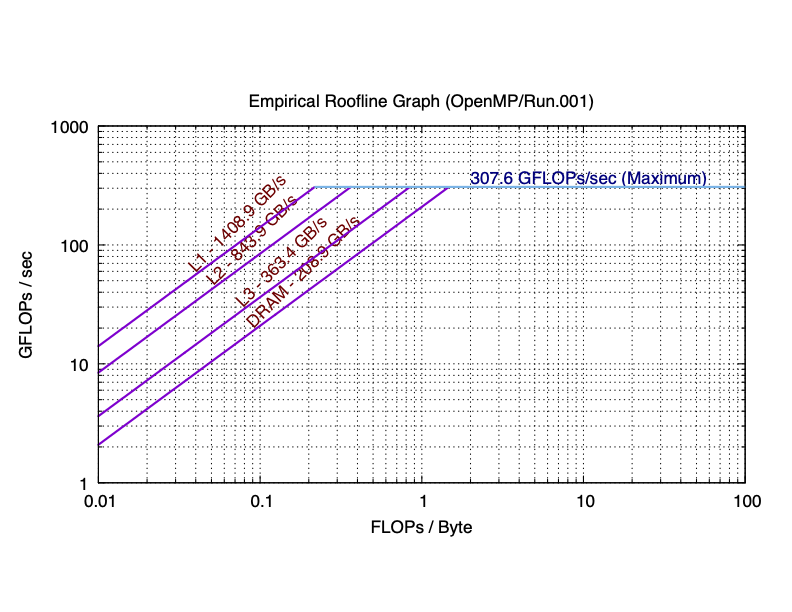
The sequential and 8 core results for a laptop are plotted as the following:
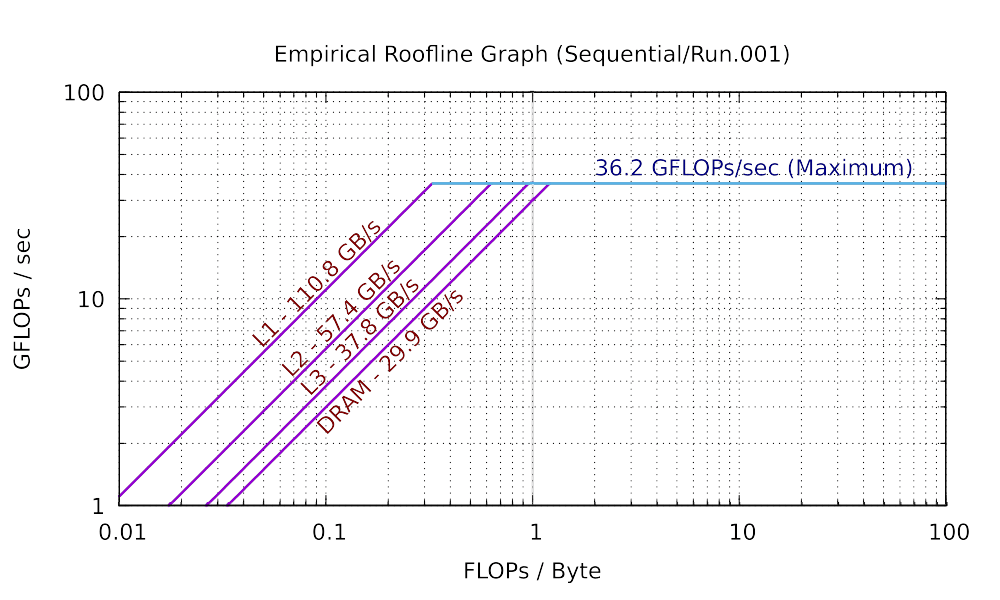
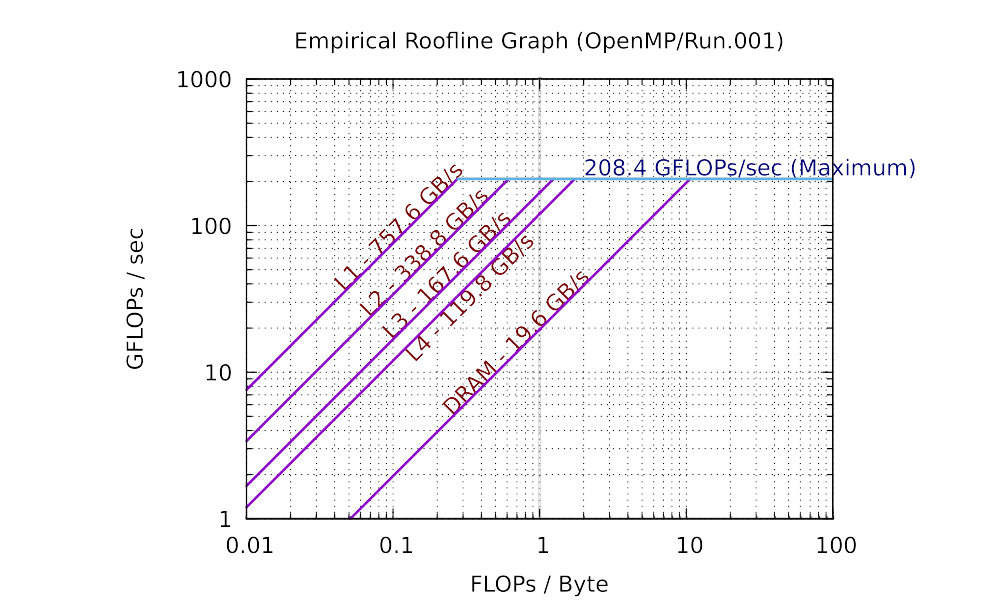
As you can see in practice, the maximum performance of 8 cores is 5.76 times (much smaller than 8 times) than the maximum performance of single core. The total bandwidth of the L1 cache of 8 cores is 6.84 times (still smaller than 8 times) than the bandwidth of the L1 cache of single core. You can observe similar trend in L2, and L3 caches. However, the bandwidth of the main memory of 8 cores is only has 66.2% of that of single core. This is because the main memory is shared among all cores. If you are not clear about why the parallel roofline model differs from the sequential roofline model, start a discussion on Discord.
If you want to refer to a roofline model when analyzing some of your results for this assignment, you can either generate your own, refer to mine above, or estimate what yours would be based on what will and will not scale with number of cores.
If you are using Apple M1 Chip or M1 Max and you are having trouble generating roofline profiles yourself, you can use the ones generated below.
Here are the sequential and parallel roofline results for an Apple M1.
As you can see in practice, the maximum performance of 8 cores (according to Apple, M1 has 4 performance cores and 4 efficiency cores) is 10 times (more than 8 times) than the maximum performance of single core. The total bandwidth of the L1 cache of 8 cores is 11.1 times (still more than 8 times) than the bandwidth of the L1 cache of single core. For L2 cache, 8-core is 7.43 times than single core. L3 cache was failed to be detected on single core. However, the bandwidth of the main memory of 8 cores is very close to that of single core. This is because the main memory is shared among all cores. If you are not clear about why the parallel roofline model differs from the sequential roofline model, start a discussion on Discord.
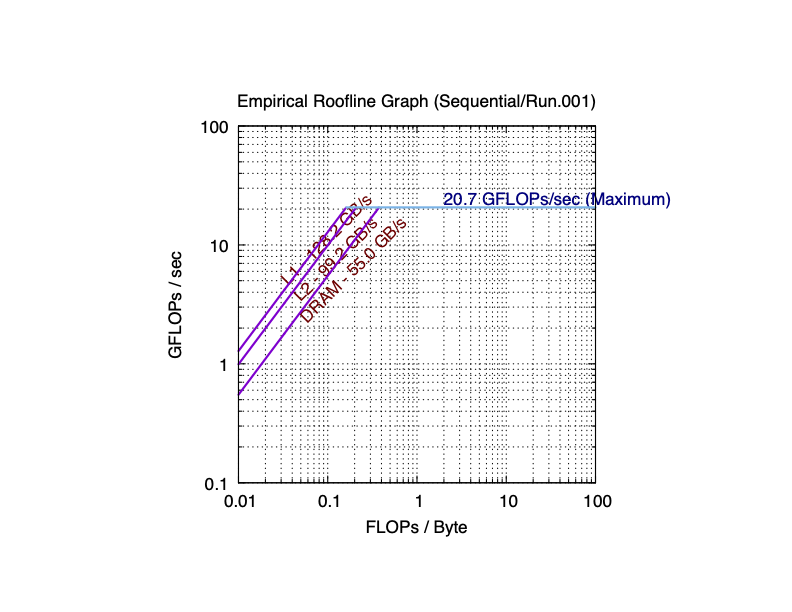
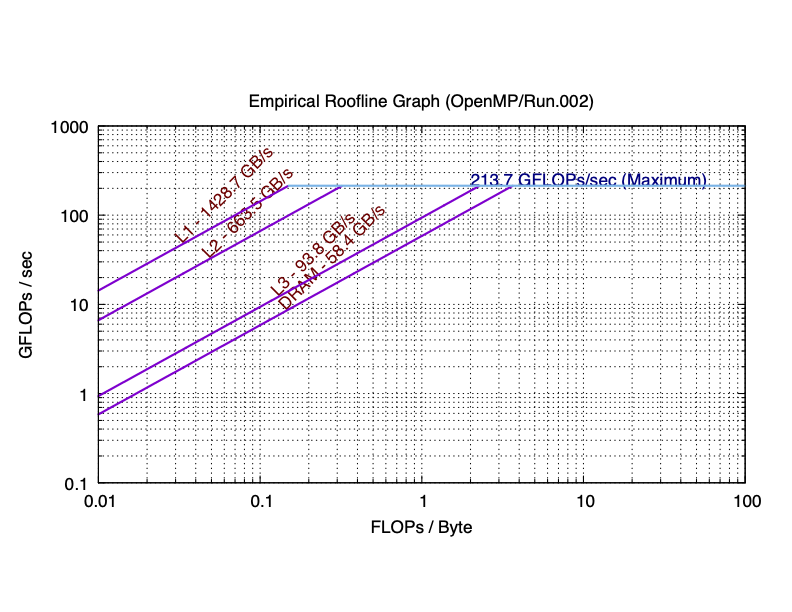
Here are the sequential and parallel roofline results for an Apple M1 Max.
For M1 Max, I leave it for you to compute the performance difference in the plots.
Extra Credit
You may or may not notice that, since L1/L2 caches are private, the total bandwidth of them is definitively (much) more than that of the single core. However, because the DRAM is shared among all cores, the comparison between the bandwidth of the DRAM of 8 cores and that of the single core is more complicated. In the first Intel-CPU plot, we see the parallel bandwidth is smaller than the sequential one. In the Apple M1 plot, the parallel bandwidth is close to the sequential one. In the Apple M1 Max, the parallel bandwidth is almost 3 times than the sequential one.
If you are interested in this phenomenon, here is a hint for you to dive deep. What is the difference between SDRAM DDR4 and SDRAM DDR5 in terms of bandwidths? Wikipedia is a good starting point for investigation. DDR4 is the SDRAM type on my Intel machine and Apple M1 machine. Intel machine has one DRAM, Apple M1 machine has two. Hence the total bandwidths of Apple M1 will be twice than the bandwidth of the Intel machine. DDR5 is the DRAM type on Apple M1 Max machine, this machine has two of them (hence the total bandwidths will double). Why such difference would cause the bandwidth difference in the sequential roofline and the parallel roofline plots? You are welcomed to share your exploration process on Discord.
The first person who shares the correct answer on Discord will get extra credit on this.
Next up: More Warmup